矩阵分解在推荐系统中的应用 NMF与经典SVD实战解析
推荐系统作为信息过滤的核心技术,已广泛应用于电商、社交、内容平台等领域。矩阵分解作为推荐系统中的经典方法,通过将高维稀疏的用户-物品交互矩阵分解为低维稠密的潜在特征矩阵,能够有效挖掘用户偏好与物品属性,从而实现精准推荐。本文将重点探讨两种核心的矩阵分解技术——非负矩阵分解与经典奇异值分解,并结合实战场景分析其应用。
一、矩阵分解的核心思想
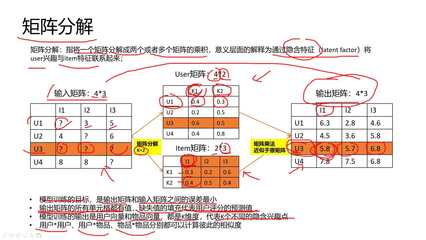
推荐系统中的矩阵分解,其目标是将用户-物品评分矩阵 \( R \in \mathbb{R}^{m \times n} \) 分解为两个(或三个)低维矩阵的乘积。例如,\( R \approx UV^T \),其中 \( U \in \mathbb{R}^{m \times k} \) 表示用户潜在特征矩阵,\( V \in \mathbb{R}^{n \times k} \) 表示物品潜在特征矩阵,\( k \ll m, n \) 为潜在特征维度。通过优化重建误差(如均方误差),模型能够学习到用户和物品的隐含特征,进而预测未知评分。
二、非负矩阵分解在推荐中的实战应用
非负矩阵分解要求分解后的所有矩阵元素非负,这使得其分解结果具有直观的可解释性——用户特征和物品特征均可视为非负的权重组合。
算法原理:给定非负矩阵 \( R \),寻找非负矩阵 \( U \) 和 \( V \),使得 \( R \approx UV^T \)。通常通过最小化损失函数 \( \|R - UV^T\|_F^2 \) 来求解,并使用梯度下降或交替最小二乘法进行优化。
实战优势:
1. 可解释性强:由于特征均为非负值,可以理解为用户对某些“主题”的偏好程度,或物品属于某些“类别”的强度。
2. 适用于隐式反馈:在处理点击、浏览等隐式反馈数据时,NMF能够有效识别用户的正向兴趣。
3. 实现简单:许多机器学习库(如scikit-learn)提供了高效的NMF实现,便于快速部署。
实战示例(Python伪代码):`python
from sklearn.decomposition import NMF
import numpy as np
假设R为用户-物品评分矩阵(非负)
R = np.array([[5, 3, 0, 1],
[4, 0, 0, 1],
[1, 1, 0, 5],
[0, 0, 4, 4]])
初始化NMF模型,设置潜在特征维度k=2
model = NMF(ncomponents=2, init='random', randomstate=42)
U = model.fittransform(R) # 用户特征矩阵
V = model.components # 物品特征矩阵
预测评分
R_pred = np.dot(U, V)`
三、经典奇异值分解在推荐中的实战应用
奇异值分解是线性代数中的经典技术,可将任意矩阵分解为三个矩阵的乘积:\( R = U \Sigma V^T \),其中 \( U \) 和 \( V \) 是正交矩阵,\( \Sigma \) 是对角矩阵。在推荐系统中,通常使用截断SVD,仅保留前 \( k \) 个最大的奇异值及其对应向量,实现降维与去噪。
算法原理:通过SVD得到 \( Rk = Uk \Sigmak Vk^T \),其中 \( k \) 为潜在特征维度。用户和物品的潜在特征可分别表示为 \( Uk \Sigmak^{1/2} \) 和 \( Vk \Sigmak^{1/2} \)。
实战优势:
1. 数学基础坚实:SVD具有严格的数学理论支持,能够有效捕捉矩阵的主要结构。
2. 降噪能力强:通过保留主要奇异值,可以过滤掉评分数据中的噪声。
3. 适用于稠密矩阵:当数据相对稠密时,SVD能提供稳定的分解结果。
挑战与改进:经典SVD要求矩阵没有缺失值,但推荐数据通常极度稀疏。因此,实践中常采用基于梯度下降的FunkSVD(即隐语义模型)或加入偏置项的SVD++,直接优化预测评分与真实评分之间的误差,从而处理缺失值问题。
实战示例(使用surprise库实现SVD):`python
from surprise import SVD, Dataset, Reader
from surprise.modelselection import traintest_split
加载数据(格式:用户ID,物品ID,评分)
data = Dataset.loadbuiltin('ml-100k')
trainset, testset = traintestsplit(data, testsize=0.25)
训练SVD模型
model = SVD(nfactors=50, randomstate=42)
model.fit(trainset)
预测评分
predictions = model.test(testset)`
四、NMF与SVD的对比与选型建议
- 数据性质:若数据为非负(如评分、点击次数),且需要可解释性,优先选择NMF;若数据为稠密矩阵或需要强数学理论支持,可考虑SVD。
- 稀疏性处理:对于极端稀疏的推荐数据,改进的SVD模型(如FunkSVD)通常比NMF更具优势。
- 计算效率:NMF通常计算复杂度较高,而SVD可通过随机算法加速,适用于大规模数据。
- 实战选择:在实际推荐系统中,常将两者作为基线模型,通过交叉验证比较性能。现代深度推荐模型(如神经矩阵分解)也常借鉴其思想。
五、与展望
矩阵分解通过降维与特征提取,为推荐系统提供了简洁而强大的建模能力。NMF以其可解释性在隐式反馈场景中表现出色,而经典SVD及其变体则在评分预测任务中历经考验。随着深度学习的发展,矩阵分解常与神经网络结合,形成更复杂的混合模型,以应对数据稀疏性、冷启动等挑战。作为基础技术,深入理解NMF与SVD的原理与实战,仍是构建高效推荐系统的关键基石。矩阵分解将继续与图神经网络、强化学习等技术融合,推动推荐系统向更智能化、个性化方向发展。
如若转载,请注明出处:http://www.njshuoma.com/product/321.html
更新时间:2026-06-19 19:46:27